MAdVerse: A Hierarchical Dataset of Multi-Lingual Ads from Diverse Sources and Categories
CVIT lab, IIIT-Hyderabad
WACV 2024
WACV 2024
Abstract
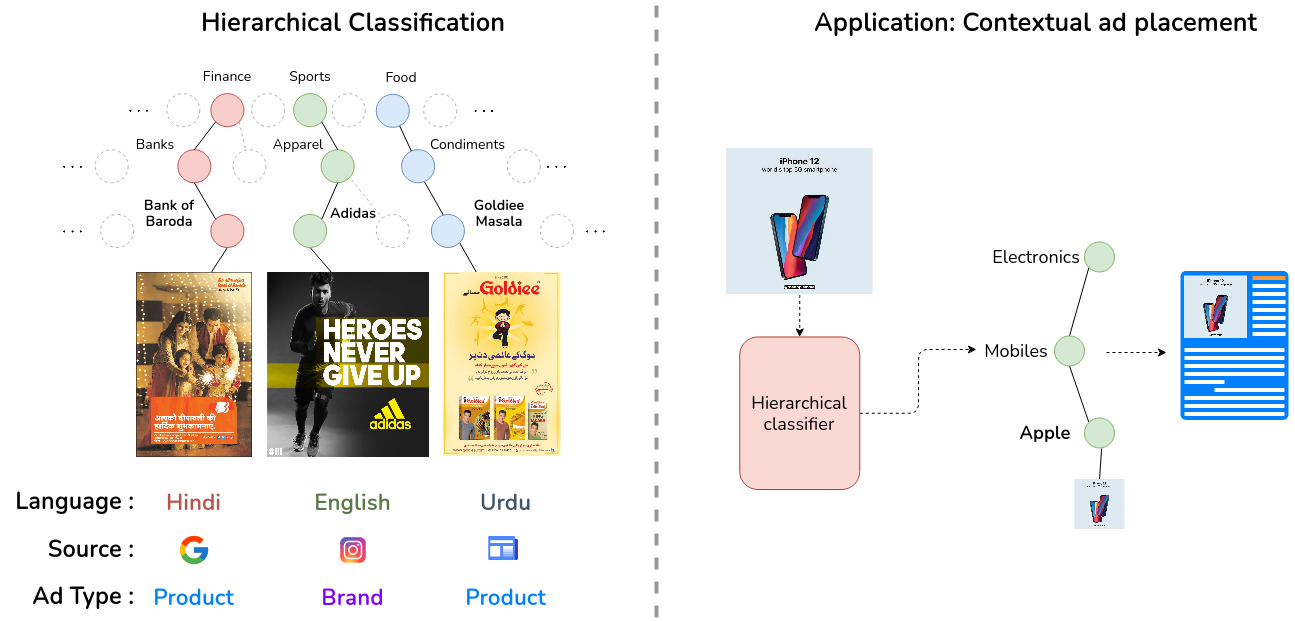
The convergence of computer vision and advertising has sparked substantial interest lately. Existing advertisement datasets often derive from subsets of established data with highly specialized annotations or feature diverse annotations without a cohesive taxonomy among ad images. Notably, no datasets encompass diverse advertisement styles or semantic grouping at various levels of granularity for a better understanding of ads. Our work addresses this gap by introducing MAdVerse, an extensive, multilingual compilation of more than 50,000 ads from the web, social media websites, and e-newspapers. Advertisements are hierarchically grouped with uniform granularity into 11 categories, divided into 51 sub-categories, and 524 finegrained brands at leaf level, each featuring ads in various languages. Furthermore, we provide comprehensive baseline classification results for various pertinent prediction tasks within the realm of advertising analysis. Specifically, these tasks include hierarchical ad classification, source classification, multilingual classification, and inducing hierarchy in existing ad datasets
| Online Ads | Advert Gallery | Newspaper Ads | |
|---|---|---|---|
| Hierarchical annotation | YES | YES | NO |
| Source of the ad | YES | YES | YES |
| Language of the ad | YES | YES | YES |
| Brand / Product | YES | YES | NO |
Hierarchy visualization
To explore the visualization:
- Click on a node to reveal its child nodes, and click on a leaf node to view associated example images.
- Hold down the left mouse button and move up/down to pan through the visualization.
- Scroll up/down to zoom in and out for a closer look.
Paper

@inproceedings{sagar2024madverse,
title = {{MAdVerse: A Hierarchical Dataset of Multi-Lingual Ads from Diverse Sources and Categories}},
author = {Amruth sagar and Rishabh Srivastava and Rakshitha and Venkata Kesav and Ravi Kiran},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2024}
}